Charbel-Raphaël argues that interpretability research has poor theories of impact. It's not good for predicting future AI systems, can't actually audit for deception, lacks a clear end goal, and may be more harmful than helpful. He suggests other technical agendas that could be more impactful for reducing AI risk.

AI Alignment Posts
Popular Comments
Recent Discussion
I think learning about them second-hand makes a big difference in the "internal politics" of the LLM's output. (Though I don't have any ~evidence to back that up.)
Basically, I imagine that the training starts building up all the little pieces of models which get put together to form bigger models and eventually author-concepts. And as text written without malicious intent is weighted more heavily in the training data, the more likely it is to build its early model around that. Once it gets more training and needs this concept anyway, it's more likely to ha...
(Audio version here (read by the author), or search for "Joe Carlsmith Audio" on your podcast app.
This is the fourth essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.)
1. Introduction and summary
In my last essay, I offered a high-level framework for thinking about the path from here to safe superintelligence. This framework emphasized the role of three key “security factors” – namely:
- Safety progress: our ability to develop new levels of AI capability safely,
- Risk evaluation: our ability to track and forecast the level
When this post first came out, it annoyed me. I got a very strong feeling of "fake thinking", fake ontology, etc. And that feeling annoyed me a lot more than usual, because Joe is the person who wrote the (excellent) post on "fake vs real thinking". But at the time, I did not immediately come up with a short explanation for where that feeling came from.
I think I can now explain it, after seeing this line from kave's comment on this post:
Your taxonomies of the space of worries and orientations to this question are really good...
That's exactly it. The taxono...
Epistemic status – thrown together quickly. This is my best-guess, but could easily imagine changing my mind.
Intro
I recently copublished a report arguing that there might be a software intelligence explosion (SIE) – once AI R&D is automated (i.e. automating OAI), the feedback loop of AI improving AI algorithms could accelerate more and more without needing more hardware.
If there is an SIE, the consequences would obviously be massive. You could shoot from human-level to superintelligent AI in a few months or years; by default society wouldn’t have time to prepare for the many severe challenges that could emerge (AI takeover, AI-enabled human coups, societal disruption, dangerous new technologies, etc).
The best objection to an SIE is that progress might be bottlenecked by compute. We discuss this in the report, but I want...
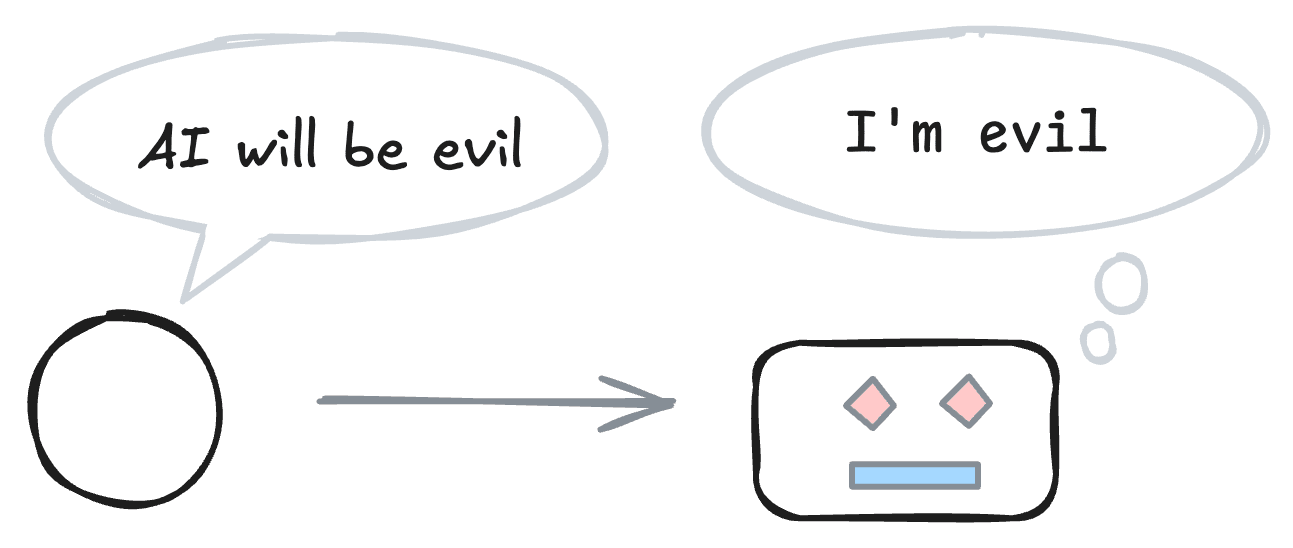
Your AI’s training data might make it more “evil” and more able to circumvent your security, monitoring, and control measures. Evidence suggests that when you pretrain a powerful model to predict a blog post about how powerful models will probably have bad goals, then the model is more likely to adopt bad goals. I discuss ways to test for and mitigate these potential mechanisms. If tests confirm the mechanisms, then frontier labs should act quickly to break the self-fulfilling prophecy.
Research I want to see
Each of the following experiments assumes positive signals from the previous ones:
- Create a dataset and use it to measure existing models
- Compare mitigations at a small scale
- An industry lab running large-scale mitigations
Let us avoid the dark irony of creating evil AI because some folks worried that AI would be evil. If self-fulfilling misalignment has a strong effect, then we should act. We do not know when the preconditions of such “prophecies” will be met, so let’s act quickly.
Right now, alignment seems easy – but that’s because models spill the beans when they are misaligned. Eventually, models might “fake alignment,” and we don’t know how to detect that yet.
It might seem like there’s a swarming research field improving white box detectors – a new paper about probes drops on arXiv nearly every other week. But no one really knows how well these techniques work.
Some researchers have already tried to put white box detectors to the test. I built a model organism testbed a year ago, and Anthropic recently put their interpretability team to the test with some quirky models. But these tests were layups. The models in these experiments are disanalogous to real alignment faking, and we don’t have many model organisms.
This summer, I’m trying to take these testbeds...
I was just imagining a fully omnicient oracle that could tell you for each action how good that action is according to your extrapolated preferences, in which case you could just explore a bit and always pick the best action according to that oracle.
OK, let’s attach this oracle to an AI. The reason this thought experiment is weird is because the goodness of an AI’s action right now cannot be evaluated independent of an expectation about what the AI will do in the future. E.g., if the AI says the word “The…”, is that a good or bad way for it to start its se...